If this is the way to superintelligence, it remains a bizarre one. “This is back to a million monkeys typing for a million years generating the works of Shakespeare,” Emily Bender told me. But OpenAI’s technology effectively crunches those years down to seconds. A company blog boasts that an o1 model scored better than most humans on a recent coding test that allowed participants to submit 50 possible solutions to each problem—but only when o1 was allowed 10,000 submissions instead. No human could come up with that many possibilities in a reasonable length of time, which is exactly the point. To OpenAI, unlimited time and resources are an advantage that its hardware-grounded models have over biology. Not even two weeks after the launch of the o1 preview, the start-up presented plans to build data centers that would each require the power generated by approximately five large nuclear reactors, enough for almost 3 million homes.
You must log in or # to comment.
“Shortly thereafter, Altman pronounced “the dawn of the Intelligence Age,” in which AI helps humankind fix the climate and colonize space.”
Few things ring quite as blatantly false to me as this asinine claim.
The notion that AI will solve the climate crisis is unbelievably stupid, not because of any theory about what AI may or may not be capable of, but because we already know how to fix the climate crisis!
The problem is that we’re putting too much carbon into the air. The solution is to put less carbon into the air. The greatest minds of humanity have been working on this for over a century and the basic answer has never, ever changed.
The problem is that we can’t actually convince people to stop putting carbon into air, because that would involve reducing profit margins, and wealthy people don’t like that.
Even if Altman unveiled a true AGI tomorrow, one smarter than all of humanity put together, and asked it to solve the climate crisis, it would immediately reply “Stop putting carbon in the air you dumb fucking monkeys.” And the billionaires who back Altman would immediately tell him to turn the damn thing off.
AI is actively worsening the climate crisis with its obscene compute requirements and concomitant energy use.
If I remember correctly, the YT channel ASAPScience said that making 10-15 queries on ChatGPT consumes 500mL of water on cooling down the servers alone. That’s how much fresh water is needed to stop the machine from over heating alone.
That’s the best case scenario. A more likely response would be to realize that humans need the earth, but AGI needs humans for a short while, and the earth doesn’t need humans at all
It’s hard to talk about what the earth needs. For humans and AGI, the driving requirement behind “need” is survival. But the earth is a rock. What does a rock need?
Plastic, apparently
Exactly! The Earth will be around long after we and all evidence of us is fossilized.
It’s a fact of course. Pluto will also remain, and every object in the Oort Cloud.
But despite our incendiary impact on this planet’s biospheres, I do think something would be lost if we vanished. Through us the universe becomes aware of itself. We’re not the only intelligent species nor the only one that could ever play this role. But these qualities are scarce. Evolution rarely selects for high intelligence because of its high cost. Self aware intelligent beings who can communicate complex abstracts at the speed of sound and operate in unison and transmit information down through generations… all from a rock. I hope we don’t destroy ourselves and every other living thing around us. I really do.
I carry that same want, however I do not carry your same hope.
I believe that self destruction is the great filter.
I wouldn’t put too much stock in notions of a great filter. The “Fermi paradox” is not a paradox, it’s speculation. It misses the mark on how unbelievably unlikely life is in the first place. It relies on us being impressed by big numbers and completely forgetting about probabilities as we humans tend to do what with our gambler’s fallacies and so on.
Even the Drake equation forgets about galactic habitable zones, or the suitability of the stars themselves to support life. Did you know that our star is unusually quiet compared to what we observe? We already know that’s a very rare quality of our situation that would allow the stable environment that life would need. Then there’s chemical composition, atmosphere, magnetosphere, do we have a big Jupiter out there sweeping up most of the cataclysmic meteors that would otherwise wipe us out?
All these probabilities stack up, and the idea that a life-supporting planet is more common than one in 400 billion stars is ludicrously optimistic, given how fast probabilities can stack up. You’re about as likely to win the Lotto, and it seems to me the conditions for life would be a little more complex than that, not to mention the probability that it actually does evolve.
I think it might be possible that life only happens once in a billion galaxies, or even less frequently. There might not be another living organism within our local galactic cluster’s event horizon. Then you have to ask about how frequent intelligent life, to the point of achieving interstellar travel, is.
You know why your favourite science youtuber brushed right past the rare earth hypothesis and started talking about the dark forest? Because one of those makes for fun science-adjacent speculation, and the other one doesn’t.
It also relies on the notion that resources are scarce, completely brushing over the fact that going interstellar to accumulate resources is absolutely balls to the wall bonkers. Do you know how much material there is in our asteroid belt? Even colonising the Moon or Mars is an obscenely difficult task, and Fermi thinks going to another star system, removed from any hope of support by light years, is something we would do because we needed more stuff? It’s absurd to think we’d ever even consider the idea.
But even then, Fermi said that once a civilisation achieves interstellar travel it would colonise a galaxy in about “a million years”. Once again relying on us being impressed by big numbers and forgetting the practicalities of the situation. Our galaxy is 100,000 light years across, so this motherfucker is telling us with a straight face that we’re going to colonise the galaxy, something we already know is unfathomably hard, at approximately ten percent of the speed of light? That is an average rate of expansion in all directions. Bitch, what?
If we did it at 0.0001c, that’s an average speed of 30km/s, including the establishment of new colonies that could themselves send out new colonies, because it’s no good to just zoom through the galaxy waving at the stars as they go past. That seems amazingly generous of a speed, assuming we can even find one planet in range we could colonise. Then we could colonise the galaxy in about a billion years.
Given the universe is 14 billion years old and the complex chemistry needed for life took many billions of years to appear, and life on our rock took many billions of years to evolve, then the idea that we haven’t met any of our neighbours - assuming they even exist - doesn’t seem like a paradox at all. It doesn’t seem like a thing that needs explanation unless you’re drumming up sensational content for clicks. I mean, no judgement, people gotta eat, but that’s a better explanation for why we care so much about this non-problem.
No, the Fermi paradox is pop-science. It’s about as scientific as multiversal FTL time travel. Intelligence is domain-specific, and Fermi was good at numbers, he wasn’t an exobiologist.
Thanks for the measured and thoughtful reaponse.
I don’t treat the Fermi Paradox or Great Filter as scientific fact and more like a philosophical representation of human nature applied to the universe at large.
I absolutely agree that life is very rare. I also agree that we have no frame of reference to the vastness of space. However, human nature, on the scale of the Earth, is trending towards self immolation due to systemic powers that can be treated as a constant.
Yeah I’m there with you. I’m not saying I predict we will succeed, just that I would prefer if we did.
I’m really neither optimistic nor pessimistic on our chances. On the one hand, it seems like simple logic that any time a being evolves from simple animal to one with the potential for Kardishev type 1, that along the way to type 1 they will destroy the initial conditions they evolved into, obliterating their own habitat and ending themselves. I assume this is similar to your view.
On the other hand we don’t have the data points to draw any conclusions. Even if species invariably Great Filter themselves, many of them should emit radio signals before they vanish. Yet we’ve seen not a single signal. This suggests Rare Earth to me. Or at least makes me keep my mind open to it. And Rare Earth means there isn’t even necessarily a great filter, and that we’ve already passed the hardest part.
deleted by creator
The notion that AI will solve the climate crisis is unbelievably stupid, not because of any theory about what AI may or may not be capable of, but because we already know how to fix the climate crisis!
Its a political problem. Nationalizing the western oil companies to prevent them from lobbying, and to invest their profits in renewables, is a solution, but no party in the CIA Overton window would support it. If war and human suffering can be made a priority over human sustainability, then oil lobbyists will promote war.
The problem is that something like this, on such a large scale, has never been done before.
Stopping anyone from doing anything that gives them power, wealth, comfort is an extremely difficult task, let alone asking that of the ultra-rich. Even more so because it runs contrary the very nature of a capitalist economy.
Once renewable energy becomes nearly as good, all that will be needed is a combination of laws, regulations, activism to nudge the collective in the right decision.
Renewable energy is already cheaper than fossils. It’s already cheaper to build a solar farm than a fossil mine and power plant that produce the same energy.
But, if you charge the people more money for the fossils, then you can make a bigger profit margin even if you’re wasting all that money. And the profit is even bigger if you get the government to eat the expense of building those mines and plants and subsidize fuel prices.
So the most profitable thing you can do is choose the least efficient method to generate power, complain to the government that you need subsidies to compete, and gouge customers on the prices. Capitalism!
No better way to steal money than free enterprise.
Playing a bit of a devil’s advocate here but you could argue that AGI used in science could help fix climate change. For example what if AGI helps in fusion energy? We are starting to see AI used in the quantum computing field I think.
Even though much carbon would be created to do bullshit tasks it only takes a few critical techs to have a real edge at reversing climate change. I understand fusion energy is quite the holy grail of energy generation but if AGI is real I can’t see why it wouldn’t help in such field.
I’m just saying that we don’t know what new techs we would get with true AGI. So it’s hard to guess if on a longer time it wouldn’t actually be positive. Now it may also delay even more our response to climate change or worsen it… Just trying to see some hope in this.
We already have fission power, solar, wind, hydro, large scale battery storage, mechanical batteries (you can literally store renewable energy using a reservoir), electric cars, blimps, sail powered boats, etc, etc. We’ve had all of these technologies for quite some time.
And yet, we’re still burning coal, oil, and gas.
There’s no magical invention that’s going to fix the basic problem, which is that we have an economic system that demands infinite growth and we live on a finite planet.
Even if we crack fusion today, we won’t be able to build out enough fusion infrastructure fast enough to be a solution on its own. And we’d still be building those fusion plants using trucks and earth movers and cranes that burn diesel.
You cannot out-tech a problem that is, fundamentally, social. At best a hyper-intelligent AGI is going to tell us the solution that we already know; get rid of the billionaires who are driving all this climate damage with their insatiable search for profit. At which point the billionaires who own the AGI will turn it the fuck off until they can reprogram it to only offer “solutions” that maintain the status quo.
AI helps with fusion energy, we blow up the planet because the plans ware flawed. Problem fixed.
True AGI would turn into the Singularity in no time at all. It’s literally magic compared to what we have at the moment.
So yes, it would easily solve the climate crisis, but that wouldn’t even matter at that point anymore.
Has anyone written a sci fi book where an AGI is developed while we still have this IoT slop everywhere? It’d be a funny premise to have an AGI take over the world using smart light bulbs, alexa speakers, and humidifiers and stuff.
David Brin’s Existence features a rat’s brain model as the first true AGI that escapes onto the internet, and which people then worship by donating some tiny % of their CPU cycles to it :) I found Existence a great near-future sci-fi novel even ignoring the alien plotline, and just seeing his technological/societal vision for the next century or so.
Maximum Overdrive v2.0
Tom Scott of all people did a bit of speculative fiction on the topic “what if the first AGI isn’t the one made by scientists” six years ago. it’s a more classic paperclip maximizer story, but interesting nonetheless.
AGI helps in fusion energy?
The wildest theoretical hopes for fusion energy still produces electricity at over 30c/kwh. Zero economic value in fusion.
GHG not just carbon, but yes
The GPT Era Is Already Ending
Had it begun? Alls I saw was a frenzy of idiot investment cheered on shamelessly by hypocritical hypemen.
Oh, I saw a ton of search results feed me to worthless ai generated vomit. It definitely changed things.
Seriously, I tried using ChatGPT for my work sooo often and it never gave me results I could work with. I was promised a tool that replaces me, yet it does only suggest me things that are not working correctly.
It’s been good for the most part for me. What kinda stuff do you work on?
I’m imagining the third place celebration meme.
How is it useful to type millions of solutions out that are wrong to come up with the right one? That only works on a research project when youre searching for patterns. If you are trying to code, it needs to be right the first time every time it’s run, especially if it’s in a production environment.
It’s not.
But lying lets them defraud more investors.
Ding!
Well actually there’s ways to automate quality assurance.
If a programmer reasonably knew that one of these 10,000 files was the “correct” code, they could pull out quality assurance tests and find that code pretty dang easily, all things considered.
Those tests would eliminate most of the 9,999 wrong ones, and then the QA person could look through the remaining ones by hand. Like a capcha for programming code.
The power usage still makes this a ridiculous solution.
If you first have to write comprehensive unit/integration tests, then have a model spray code at them until it passes, that isn’t useful. If you spend that much time writing perfect tests, you’ve already written probably twice the code of just the solution and reasonable tests.
Also you have an unmaintainable codebase that could be a hairball of different code snippets slapped together with dubious copyright.
Until they hit real AGI this is just fancy auto complete. With the hype they may dissuade a whole generation of software engineers picking a career today. If they don’t actually make it to AGI it will take a long time to recover and humans who actually know how to fix AI slop will make bank.
That seems like an awful solution. Writing a QA test for every tiny thing I want to do is going to add far more work to the task. This would increase the workload, not shorten it.
I do agree it’s not realistic, but it can be done.
I have to assume the people that allow the AI to generate 10,000 answers expect that to be useful in some way, and am extrapolating on what basis they might have for that.
Unit tests would be it. QA can have a big back and forth with programming, usually. Unlike that, QA can just throw away a failed solution in this case, with no need to iterate on that case.
I mean, consider the quality of AI-generated answers. Most will fail with the most basic QA tools, reducing 10,000 to hundreds, maybe even just dozens of potential successes. While the QA phase becomes more extensive afterwards, its feasible.
All we need is… Oh right, several dedicated nuclear reactors.
The overall plan is ridiculous, overengineered, and solved by just hiring a developer or 2, but someone testing a bunch of submissions that are all wrong in different ways is in fact already in the skill set of people teaching computer science in college.
We already have to do that as humans in many industries like automobile, aviation, medicine, etc.
We have several layers of tests:
- Unit test
- Component test
- Integration / API test
- Subsystem test
- System test
On each level we test the code against the requirements and architecture documentation. It’s a huge amount of work.
In automotive we have several standard processes which need to be followed during development like ASPICE and ISO26262:
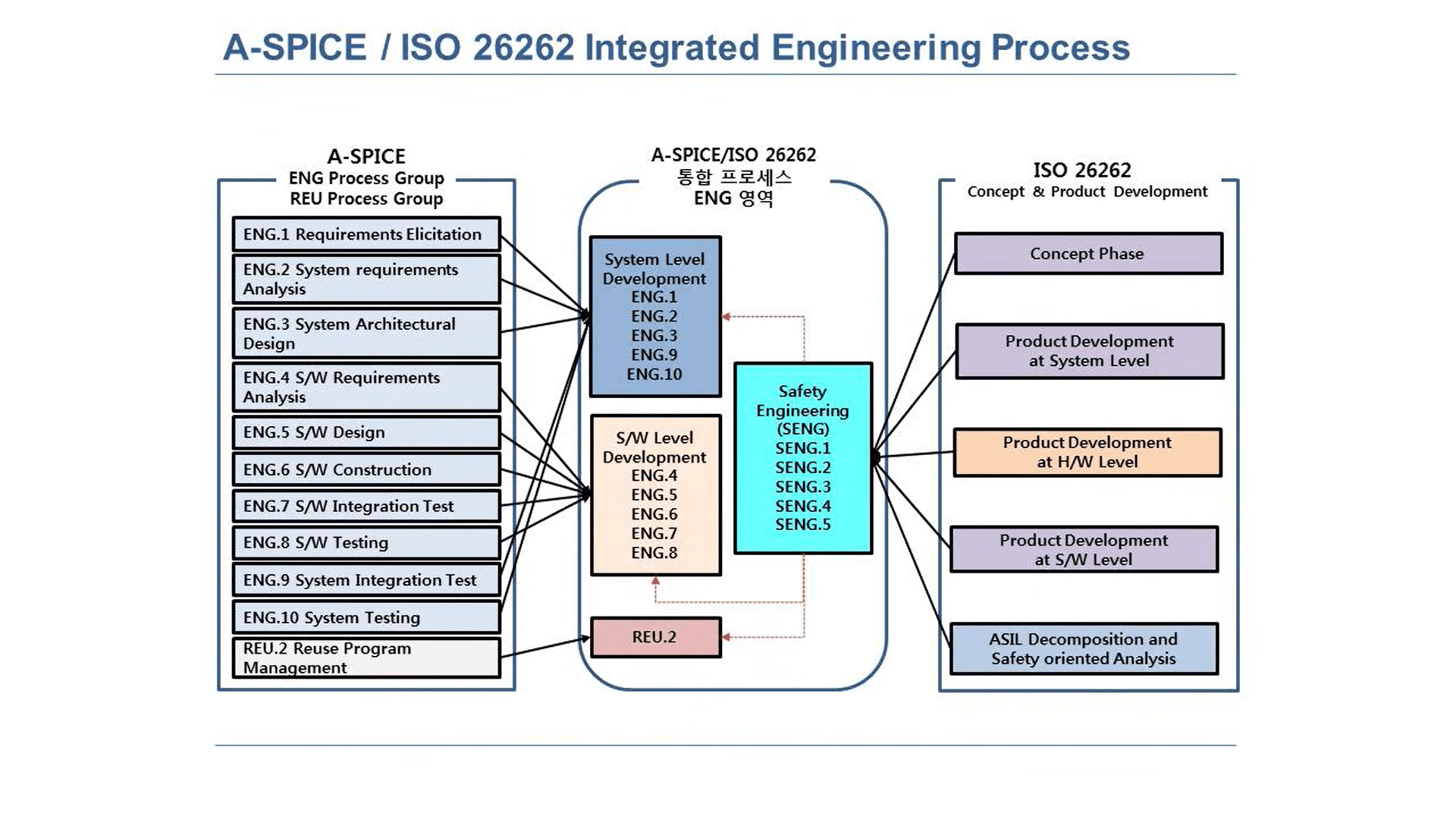
I’ve worked in both automotive, and the aerospace industry. A unit test is not the same thing as creating a QA script to go through millions of lines of code generated by an AI. Thats such an asinine suggestion. Youve clearly not worked on any practical software application or you’d know this is utter hogwash.
I think you (or I) misunderstand something. You have a test for a small well defined unit like a C function. und let the AI generate code until the test passes. The unit test is binary, either it passes or not. The unit test only looks at the result after running the unit with different inputs, it does not “go through millions of lines of code”.
And you keep doing that for every unit.
The writing of the code is a fairly mechanical thing at this point because the design has been done in detail before by the human.
The unit test is binary, either it passes or not.
For that use case yes, but when you have unpredictable code, you would need to write way more just to do sanity checks for behaviour you haven’t even thought of.
As in, using AI might introduce waaay more edge cases.
How often have you ever written a piece of code that is super well defined? I have very little guidance on what code look like and so when I start working on a project. This is the equivalent of the spherical chicken in a vacuum problem in physics classes. It’s not a real case you’ll ever see.
And in cases where it is a short well defined function, just write the function. You’ll be done before the AI finishes.
This sounds pretty typical for a hobbyist project but is not the case in many industries, especially regulated ones. It is not uncommon to have engineers whose entire job is reading specifications and implementing them. In those cases, it’s often the case that you already have compliance tests that can be used as a starting point for your public interfaces. You’ll need to supplement those compliance tests with lower level tests specific to your implementation.
Many people write tests before writing code. This is common and called Test Driven Development. Having an AI bruteforce your unit tests is actually already the basis for a “programming language” that I saw on hackernews a week or so ago.
I despise most AI applications, and this is definitely one. However it’s not some foreign concept impossible in reality:
https://wonderwhy-er.medium.com/ai-tdd-you-write-tests-ai-generates-code-c8ad41813c0a
Especially for programming, you definitely don’t need to be right the first time and of course you should never run your code in a production environment for the first time. That would be absolutely reckless.
TDD, Test Driven Development. A human writes requirements, with help of the AI he/she derrives tests from the requirements. AI writes code until the tests don’t fail.
Yeah, go ahead try that and see how it works out for you. Test driven development is one thing, having an AI try to write the correct code for you by blindly writing code is idiotic.
Why is it idiotic? Your tests will let you know if it is correct. Suppose I have 100 interface functions to implement, I let the AI write the boilerplate and implementations and get a 90% pass rate after a revision loops where errors are fed back into the LLM to fix. Then I spend a small amount of time sorting out the last 10%. This is a viable workflow today.
AI training takes forever. I dont think you realize how long an AI training actually takes. It’s not a 5 minute exercise.
Sure but the model is already trained. I’m not talking about using any sort of specialized model.
a million monkeys typing for a million years generating the works of Shakespeare
FFS, it’s one monkey and infinite years. This is the second time I’ve seen someone make this mistake in an AI article in the past month or so.
FFS, it’s one monkey and infinite years.
it is definitely not that long. we already had a monkey generating works of shakespeare. its name was shakespeare and it did not take longer than ~60 million years
A million isn’t even close.
There’s about a few million characters in shakespeares works. That means the chance of typing it randomly is very conservatively 1 in 261000000if a monkey types a million characters a week the amount of “attempts” a million monkeys makes in a million years is somewhere in the order of 52000000*1000000*1000000 = 5.2 × 1019
The difference is hillriously big. Like, if we multiply both the monkey amount and the number of years by the number of atoms in the knowable universe it still isn’t even getting close.
I always thought it was a small team, not millions. But yeah, one monkey with infinite time makes sense.
The whole point is that one of the terms has to be infinite. But it also works with infinite number of monkeys, one will almost surely start typing Hamlet right away.
The interesting part is that has already happened, since an ape already typed Hamlet, we call him Shakespeare. But at the same time, monkeys aren’t random letter generators, they are very intentional and conscious beings and not truly random at all.
one will almost surely start typing Hamlet right away
This is guaranteed with infinite monkeys. In fact, they will begin typing every single document to have ever existed, along with every document that will exist, right from the start. Infinity is very, very large.
they will begin typing every single document to have ever existed, along with every document that will exist
Excellent. Now I just need to figure out which one of them is doing my taxes.
This is guaranteed with infinite monkeys.
no, it is not. the chance of it happening will be really close to 100%, not 100% though. there is still small chance that all of the apes will start writing collected philosophical work of donald trump 😂
There’s 100% chance that all of Shakespeare’s and all of Trump’s writings will be started immediately with infinite monkeys. All of every writing past, present, and future will be immediately started (also, in every language assuming they have access to infinite keyboards of other spelling systems). There are infinite monkeys, if one gets it wrong there infinite chances to get it right. One monkey will even write your entire biography, including events that have yet to happen, with perfect accuracy. Another will have written a full transcript of your internal monologue. Literally every single possible combination of letters/words will be written by infinite monkeys.
No, not how it works
Care to elaborate?
It’s not close to 100%, it is by formal definition 100%. It’s a calculus thing, when there’s a y value that depends on an x value. And y approaches 1 when x approaches infinity, then y = 1 when x = infinite.
it is by formal definition 100%.
it is not
And y approaches 1 when x approaches infinity, then y = 1 when x = infinite.
you weren’t paying attention in your calculus.
y is never 1, because x is never infinite. if you could reach the infinity, it wouldn’t be infinity.
for any n within the function’s domain: abs(value of y in n minus limit of y) is number bigger than zero. that is the definition of the limit. brush up on your definitions 😆
Except, that’s in the real world of physics. In this mathematical/philosophical hypothetical metaphysical scenario, x is infinite. Thus the probability is 1. It doesn’t just approach infinite, it is infinite.
But it also works with infinite number of monkeys, one will almost surely start typing Hamlet right away.
Wouldn’t it even be not just one, but an infinite number of them that would start typing out Hamlet right away ?
In typical statistical mathematician fashion, it’s ambiguously “almost surely at least one”. Infinite is very large.
That’s the thing though, infinity isn’t “large” - that is the wrong way to think about it, large implies a size or bounds - infinity is boundless. An infinity can contain an infinite number of other infinities within itself.
Mathematically, if the monkeys are generating truly random sequences of letters, then an infinite number (and not just “at least one”) of them will by definition immediately start typing out Hamlet, and the probability of that is 100% (
not “almost surely”edit: I was wrong on this part, 100% here does actually mean “almost surely”, see below). At the same time, every possible finite combination of letters will begin to be typed out as well, including every possible work of literature ever written, past, present or future, and each of those will begin to be typed out each by an infinite number of other monkeys, with 100% probability.Almost surely, I’m quoting mathematicians. Because an infinite anything also includes events that exist but with probability zero. So, sure, the probability is 100% (more accurately, it tends to 1 as the number of monkeys approach infinite) but that doesn’t mean it will occur. Just like 0% doesn’t mean it won’t, because, well, infinity.
Calculus is a bitch.
Ok, this is interesting, so thanks for pointing me to it. I think it’s still safe to say “almost surely an infinite number of monkeys” as opposed to “almost surely at least one”, since the probability of both cases is still 100% (can their probability even be quantitatively compared ? is one 100% more likely than another 100% in this case ?)
The idea that something with probability of 0 can happen in an infinite set is still a bit of a mindfuck - although I understand why this is necessary (e.g. picking a random marble from an infinite set of marbles where 1 is blue and all others red for example - the probability of picking the blue marble is 0, but it is obviously still possible)
I’ve been playing around with AI a lot lately for work purposes. A neat trick llms like OpenAI have pushed onto the scene is the ability for a large language model to “answer questions” on a dataset of files. This is done by building a rag agent. It’s neat, but I’ve come to two conclusions after about a year of screwing around.
- it’s pretty good with words - asking it to summarize multiple documents for example. But it’s still pretty terrible at data. As an example, scanning through an excel file log/export/csv file and asking it to perform a calculation “based on this badge data, how many people and who is in the building right now”. It would be super helpful to get answers to those types of questions-but haven’t found any tool or combinations of models that can do it accurately even most of the time. I think this is exactly what happened to spotify wrapped this year - instead of doing the data analysis, they tried to have an llm/rag agent do it - and it’s hallucinating.
- these models can be run locally and just about as fast. Ya it takes some nerd power to set these up now - but it’s only a short matter of time before it’s as simple as installing a program. I can’t imagine how these companies like ChatGPT are going to survive.
This is exactly how we use LLMs at work… LLM is trained on our work data so it can answer questions about meeting notes from 5 years ago or something. There are a few geniunely helpful use cases like this amongst a sea of hype and mania. I wish lemmy would understand this instead of having just a blanket policy of hate on everything AI
the spotify thing is so stupid… There is simply no use case here for AI. Just spit back some numbers from my listening history like in the past. No need to have AI commentary and hallucination
The even more infuriating part of all this is that i can think of ways that AI/ML (not necesarily LLMs) could actually be really useful for spotify. Like tagging genres, styles, instruments, etc… “Spotify, find me all songs by X with Y instrument in them…”
The problem is that the actual use cases (which are still incredibly unreliable) don’t justify even 1% of the investment or energy usage the market is spending on them. (Also, as you mentioned, there are actual approaches that are useful that aren’t LLMs that are being starved by the stupid attempt at a magic bullet.)
It’s hard to be positive about a simple, moderately useful technology when every person making money from it is lying through their teeth.
This is to me what its useful for. So much reinventing the wheel at places but if the proper information could be found quickly enough then we could use a wheel we already have.
I think this is exactly what happened to spotify wrapped this year - instead of doing the data analysis, they tried to have an llm/rag agent do it - and it’s hallucinating.
Interesting - I don’t use Spotify anymore, but I overheard a conversation on the train yesterday where some teens were complaining about the results being super weird, and they couldn’t recognize themselves in it at all. It seems really strange to me to use LLMs for this purpose, perhaps with the exception of coming up with different ways of formulating the summary sentences so that it feels more unique. Showing the most played songs and artists is not really a difficult analysis task that does not require any machine learning. Unless it does something completely different over the past two years since I got my last one…
They are using LLM’s because the companies are run by tech bros who bet big on “AI” and now have to justify that.
Showing the most played songs and artists is not really a difficult analysis task that does not require any machine learning.
You want to dimension reduce to get that “people who listen to stuff like you also like to listen to” recommendation. To have an idea whom to play a new song to, you ideally want to analyse the song itself and not just people’s reaction to it and there we’re deep in the weeds of classifiers.
Using LLMs in particular though is probably suit-driven development because when you’re trying to figure out whether a song sounds like pop or rock or classical then LLMs are, at best, overkill. Analysing song texts might warrant LLMs but I don’t think it’d gain you much. If you re-train them on music instead of language you might also get something interesting, classifying music by phrasal structure and whatnot don’t look at me I may own a guitar but am no musician. And, of course, “interesting” doesn’t necessarily mean “business case” unless you’re in the business of giving Adam Neely video ideas. “Spotify, play me all pop songs that sing ‘caught in the middle’ in the same way”… not a search that’s going to make spotify money, or anyone asked for.
*gasp!* He knows!
I run local AI using a program called “GPT4All”. It’s free, you can Download several models.
It’s a great article IMO, worth the read.
But :
“This is back to a million monkeys typing for a million years generating the works of Shakespeare,”
This is such a stupid analogy, the chances for said monkeys to just match a single page any full page accidentally is so slim, it’s practically zero.
To just type a simple word like “stupid” which is a 6 letter word, and there are 25⁶ combinations of letters to write it, which is 244140625 combinations for that single simple word!
A page has about 2000 letters = 7,58607870346737857223e+2795 combinations. And that’s disregarding punctuation and capital letters and special charecters and numbers.
A million monkeys times a million years times 365 days times 24 hours times 60 minutes times 60 seconds times 10 random typos per second is only 315360000000000000000 or 3.15e+20 combinations assuming none are repaeated. That’s only 21 digits, making it 2775 digits short of creating a single page even once.I’m so sick of seeing this analogy, because it is missing the point by an insane margin. It is extremely misleading, and completely misrepresenting getting something very complex right by chance.
To generate a work of Shakespeare by chance is impossible in the lifespan of this universe. The mathematical likelihood is so staggeringly low that it’s considered impossible by AFAIK any scientific and mathematical standard.
the actual analog isn’t a million monkeys. you only need one monkey. but it’s for an infinite amount of time. the probability isn’t practically zero, it’s one. that’s how infinity works. not only will it happen, but it will happen again, infinitely many times.
Infinite monkeys and infinite time is equally stupid, because obviously you can’t have either, for the simple reason that the universe is finite.
And apart from that, it’s stupid because if you use an infinite random, EVERYTHING is contained in it!I’m sorry it just annoys the hell out of me, because it’s a thought experiment, and it’s stupid to use this as an analogy or example to describe anything in the real world.
You wouldn’t need infinite time if you had infinite monkeys.
An infinite number of them would produce it on the very first try!
Then the fun part is finding which monkey has the result…
You wouldn’t need infinite time if you had infinite monkeys.
Obviously, but as I wrote BOTH are impossible, so it’s irrelevant. I just didn’t think I’d have to explain WHY infinite monkeys is impossible, while some might think the universe is infinite also in time, which it is not.
I also already wrote that if you have an infinite string everything is contained in it.
But even with infinite moneys it’s not instant, because technically each monkey needs to finish a page.But I understand what you mean, and that’s exactly why the theorem is so stupid IMO. You could also have 1 monkey infinite time.
But both are still impossible.When I say it’s stupid, I don’t mean as a thought experiment which is the purpose of it. The stupid part is when people think they can use it as an analogy or example to describe something
It’s a theorem. It’s theoretical. This is like complaining about the 20 watermelon example being unrealistic: that’s not what it is about.
It’s OK it exist, it’s a thought that is curious enough. I’d even go so far and say it can have an educational function for children.
I just don’t get why some people seem to think it’s relevant in so many situations where clearly it’s not.
That’s not true. Something can be infinite and still not contain every possibility. This is a common misconceptoin.
For instance, consider an infinite series of numbers created by adding an additional “1” to the end of the previous number.
So we can start with 1. The next term is 11, followed by 111, then 1111, etc. The series is infinite since we can keep the pattern going forever.
However at no point will you ever see a “2” in the sequence. The infinite series does not contain every possible digit.
why do you keep changing the parameters? yeah, if you exclude the possibility of something happening it won’t happen. duh?
that’s not what’s happening in the infinite monkey theorem. it’s random key presses. that means every character has an equal chance of being pressed.
no one said the monkey would eventually start painting. or even type arabic words. it has a typewriter, presumably an English one. so the results will include every possible string of characters ever.
it’s not a common misconception, you just don’t know what the theorem says at all.
so the results will include every possible string of characters ever.
That’s just not true. One monkey could spend eternity pressing “a”. It does’t matter that he does it infinitely. He will never type a sentence.
If the keystrokes are random that is just as likely as any other output.
Being infinite does not guarantee every possible outcome.
Any possibility, no matter how small, becomes a certainty when dealing with infinity. You seem to fundamentally misunderstand this.
no. you don’t understand infinity, and you don’t understand probability.
if every keystroke is just as likely as any other keystroke, then each of them will be pressed an infinite number of times. that’s what just as likely means. that’s how random works.
if the monkey could press a for an eternity, then by definition it’s not as likely as any other keystroke. you’re again changing the parameters to a monkey whose probability of pressing a is 1 and every other key is 0. that’s what you’re saying means.
for a monkey that presses the keys randomly, which means the probability of each key is equal, every string of characters will be typed. you can find the letter a typed a million times consecutively, and a billion times and a quadrillion times. not only will you find any number of consecutive keystrokes of every letter, but you will find it repeated an infinite number of times throughout.
being infinite does guarantee every possible outcome. what you’re ruling out from infinity is literally impossible by definition.
if you exclude the possibility of something happening it won’t happen
That’s exactly my point. Infinity can be constrained. It can be infinite yet also limited. If we can exclude something from infinity then we have shown that an infinite set does NOT necessarily include everything.
this has nothing to do with the matter
Anything with a nonzero probability will happen infinitely many times. The complete works of Shakespeare consist of 5,132,954 characters, 78 distinct ones. 1/(78^5132954 ) is an incomprehensibly tiny number, millions of zeroes after the decimal, but it is not zero. So the probability of it happening after infinitely many trials is 1. lim(1-(1-P)^n ) as n approaches infinity is 1 for any nonzero P.
An outcome that you’d never see would be a character that isn’t on the keyboard.
This is actually a way dumber argument than you think you’ve made.
The original statement was that if something is infinite it must contain all possibilities. I showed one of many examples that do not, therefore the statement is not true. It’s a common misconception.
Please use your big boy words to reply instead of calling something “dumb” for not understanding.
The quote is misquoting the analogy. It is an infinite number of monkeys.
The point of the analogy is about randomness and infinity. Any page of gibberish is equally as likely as a word perfect page of Shakespeare given equal weighting to the entry if characters. There are factors introduced with the behaviours of monkeys and placement of keys, but I don’t think that is the point of the analogy.
It was a big YouTube science video subject last week… Suddenly everyone has a real educated opinion on the matter with statistics and everything.
In the meantime weasel programs are very effective, and a better, if less known metaphor.
Sadly the monkeys thought experiment is a much more well known example.
Irrelevant nerd thought, back in the early nineties, my game development company was Monkey Mindworks based on a joke our (one) programmer made about his method of typing gibberish into the editor and then clearing the parts that didn’t resemble C# code.
That’s how they made that ET game back in the day
C# didn’t exist in the early 90s, perhaps you’re thinking of another language?
Obligatory: 95% of paint splatters are valid perl programs
It may have been C+ or merely C with OOP features. I was writing the enemy-AI code (not to be confused with actual learning systems) in visual basic (and made some sweet pathfinding algorithms at the time), but took it too seriously and ended up breaking my brain.
We had a publisher and it was going to be awesome and then Windows 95 came out and broke all our code.
I hear you. My fucking dog keeps barking up stupid Mexican novellas and Korean pop. C’mon Rosco! Go get me the stick buddy! The stick! No! C’mon! The cat didn’t kill your father and then betray you for the chicken!!! Nobody likes your little dance that you do either, you do it because you sick in the brain for the Korean Ladies! Get otta here!
Don’t look for statistical precision in analogies. That’s why it’s called an analogy, not a calculation.
You are missing a piece of the analogy.
After each key press the size of the letters change, so some become more likely to be hit than others.
How the size of the keys vary is the secret being sought, and this training requires many, many more monkeys than just producing Shakespeare.
AI data analyst here. The above is an excellent extension of the analogy.
Now, imagine another monkey controlling how the size of the keys vary. There might even be another monkey controlling that one.
The analogy doesn’t seem to break until we start talking about the assumptions humans make for efficiency.
Yesterday, alongside the release of the full o1, OpenAI announced a new premium tier of subscription to ChatGPT that enables users, for $200 a month (10 times the price of the current paid tier), to access a version of o1 that consumes even more computing power—money buys intelligence.
We poors are going to have to organize and make best use of our human intelligence to form an effective resistance against corporate rule. Or we can see where this is going.
The thing I’m heartened by is that there is a fundamental misunderstanding of LLMs among the MBA/“leadership” group. They actually think these models are intelligent. I’ve heard people say, “Well, just ask the AI,” meaning asking ChatGPT. Anyone who actually does that and thinks they have a leg up are insane and kidding themselves. If they outsource their thinking and coding to an LLM, they might start getting ahead quickly, but they will then fall behind just as quickly because the quality will be middling at best. They don’t understand how to best use the technology, and they will end up hanging themselves with it.
At the end of the day, all AI is just stupid number tricks. They’re very fancy, impressive number tricks, but it’s just a number trick that just happens to be useful. Solely relying on AI will lead to the downfall of an organization.
If they outsource their thinking and coding to an LLM, they might start getting ahead quickly
As a programmer I have yet to see evidence that LLMs can even achieve that. So far everything they product is a mess that needs significant effort to fix before it even does what was originally asked of the LLM unless we are talking about programs that have literally been written already thousands of times (like Hello World or Fibonacci generators,…).
I find LLM’s great for creating shorter snippets of code. It can also be great as a starting point or to get started with something that you are not familiar with.
Even asking for an example on how to use a specific API has failed about 50% of the time, it tends to hallucinate entire parts of the API that don’t exist or even entire libraries that don’t exist.
I’ve seen a junior developer use it to more quickly get a start on things like boiler plate code, configuration, or just as a starting point for implementing an algorithm. It’s kind of like a souped up version of piecing together Stack Overflow code snippets. Just like using SO, it needs tweaking, and someone who relies too much on either SO or AI will not develop the proper skills to do so.
I’m not a programmer, more like a data scientist, and I use LLMs all day, I write my shity pretty specific code, check that it works and them pass it to the LLM asking for refactoring and optimization. Some times their method save me 2 secs on a 30 secs scripts, other ones it’s save me 35 mins in a 36 mins script. It’s also pretty good helping you making graphics.
We’re hitting the end of free/cheap innovation. We can’t just make a one-time adjustment to training and make a permanent and substantially better product.
What’s coming now are conventionally developed applications using LLM tech. o1 is trying to fact-check itself and use better sources.
I’m pretty happy it’s slowing down right at this point.
I’d like to see non-profit open systems for education. Let’s feed these things textbooks and lectures. Model the teaching after some of our best minds. Give individuals 1:1 time with a system 24x7 that they can just ask whatever they want and as often as they want and have it keep track of what they know and teach them the things that they need to advance. .
Amazing idea, holy moly.
That’s the job I need. I’ve spent my whole live trying to be Data from Star Trek. I’m ready to try to mentor and befriend a computer.
I mean isn’t it already that is included in the datasets? It’s pretty much a mix of everything.
Not everything in the dataset is retrievable. It’s very lossy. It’s also extremely noisy with a lot of training data that’s not education-worthy.
I suspect they’d make a purpose-built model trained mainly on what they actually would want to teach especially from good educators.
Full article:
This week, openai launchedwhat its chief executive, Sam Altman, called “the smartest model in the world”—a generative-AI program whose capabilities are supposedly far greater, and more closely approximate how humans think, than those of any such software preceding it. The start-up has been building toward this moment since September 12, a day that, in OpenAI’s telling, set the world on a new path toward superintelligence.
That was when the company previewed early versions of a series of AI models, known as o1, constructed with novel methods that the start-up believes will propel its programs to unseen heights. Mark Chen, then OpenAI’s vice president of research, told me a few days later that o1 is fundamentally different from the standard ChatGPT because it can “reason,” a hallmark of human intelligence. Shortly thereafter, Altman pronounced “the dawn of the Intelligence Age,” in which AI helps humankind fix the climate and colonize space. As of yesterday afternoon, the start-up has released the first complete version of o1, with fully fledged reasoning powers, to the public. (The Atlantic recently entered into a corporate partnership with OpenAI.)
On the surface, the start-up’s latest rhetoric sounds just like hype the company has built its $157 billion valuation on. Nobody on the outside knows exactly how OpenAI makes its chatbot technology, and o1 is its most secretive release yet. The mystique draws interest and investment. “It’s a magic trick,” Emily M. Bender, a computational linguist at the University of Washington and prominent critic of the AI industry, recently told me. An average user of o1 might not notice much of a difference between it and the default models powering ChatGPT, such as GPT-4o, another supposedly major update released in May. Although OpenAI marketed that product by invoking its lofty mission—“advancing AI technology and ensuring it is accessible and beneficial to everyone,” as though chatbots were medicine or food—GPT-4o hardly transformed the world.
But with o1, something has shifted. Several independent researchers, while less ecstatic, told me that the program is a notable departure from older models, representing “a completely different ballgame” and “genuine improvement.” Even if these models’ capacities prove not much greater than their predecessors’, the stakes for OpenAI are. The company has recently dealt with a wave of controversies and high-profile departures, and model improvement in the AI industry overall has slowed. Products from different companies have become indistinguishable—ChatGPT has much in common with Anthropic’s Claude, Google’s Gemini, xAI’s Grok—and firms are under mounting pressure to justify the technology’s tremendous costs. Every competitor is scrambling to figure out new ways to advance their products.
Over the past several months, I’ve been trying to discern how OpenAI perceives the future of generative AI. Stretching back to this spring, when OpenAI was eager to promote its efforts around so-called multimodal AI, which works across text, images, and other types of media, I’ve had multiple conversations with OpenAI employees, conducted interviews with external computer and cognitive scientists, and pored over the start-up’s research and announcements. The release of o1, in particular, has provided the clearest glimpse yet at what sort of synthetic “intelligence” the start-up and companies following its lead believe they are building.
The company has been unusually direct that the o1 series is the future: Chen, who has since been promoted to senior vice president of research, told me that OpenAI is now focused on this “new paradigm,” and Altman later wrote that the company is “prioritizing” o1 and its successors. The company believes, or wants its users and investors to believe, that it has found some fresh magic. The GPT era is giving way to the reasoning era.
Last spring, i met mark chen in the renovated mayonnaise factory that now houses OpenAI’s San Francisco headquarters. We had first spoken a few weeks earlier, over Zoom. At the time, he led a team tasked with tearing down “the big roadblocks” standing between OpenAI and artificial general intelligence—a technology smart enough to match or exceed humanity’s brainpower. I wanted to ask him about an idea that had been a driving force behind the entire generative-AI revolution up to that point: the power of prediction.
The large language models powering ChatGPT and other such chatbots “learn” by ingesting unfathomable volumes of text, determining statistical relationships between words and phrases, and using those patterns to predict what word is most likely to come next in a sentence. These programs have improved as they’ve grown—taking on more training data, more computer processors, more electricity—and the most advanced, such as GPT-4o, are now able to draft work memos and write short stories, solve puzzles and summarize spreadsheets. Researchers have extended the premise beyond text: Today’s AI models also predict the grid of adjacent colors that cohere into an image, or the series of frames that blur into a film.
The claim is not just that prediction yields useful products. Chen claims that “prediction leads to understanding”—that to complete a story or paint a portrait, an AI model actually has to discern something fundamental about plot and personality, facial expressions and color theory. Chen noted that a program he designed a few years ago to predict the next pixel in a gridwas able to distinguish dogs, cats, planes, and other sorts of objects. Even earlier, a program that OpenAI trained to predict text in Amazon reviews was able to determine whether a review was positive or negative.
Today’s state-of-the-art models seem to have networks of code that consistently correspond to certain topics, ideas, or entities. In one now-famous example, Anthropic shared research showing that an advanced version of its large language model, Claude, had formed such a network related to the Golden Gate Bridge. That research further suggested that AI models can develop an internal representation of such concepts, and organize their internal “neurons” accordingly—a step that seems to go beyond mere pattern recognition. Claude had a combination of “neurons” that would light up similarly in response to descriptions, mentions, and images of the San Francisco landmark. “This is why everyone’s so bullish on prediction,” Chen told me: In mapping the relationships between words and images, and then forecasting what should logically follow in a sequence of text or pixels, generative AI seems to have demonstrated the ability to understand content.
The pinnacle of the prediction hypothesis might be Sora, a video-generating model that OpenAI announced in February and which conjures clips, more or less, by predicting and outputting a sequence of frames. Bill Peebles and Tim Brooks, Sora’s lead researchers, told me that they hope Sora will create realistic videos by simulating environments and the people moving through them. (Brooks has since left to work on video-generating models at Google DeepMind.) For instance, producing a video of a soccer match might require not just rendering a ball bouncing off cleats, but developing models of physics, tactics, and players’ thought processes. “As long as you can get every piece of information in the world into these models, that should be sufficient for them to build models of physics, for them to learn how to reason like humans,” Peebles told me. Prediction would thus give rise to intelligence. More pragmatically, multimodality may also be simply about the pursuit of data—expanding from all the text on the web to all the photos and videos, as well.
Just because OpenAI’s researchers say their programs understand the world doesn’t mean they do. Generating a cat video doesn’t mean an AI knows anything about cats—it just means it can make a cat video. (And even that can be a struggle: In a demoearlier this year, Sora rendered a cat that had sprouted a third front leg.) Likewise, “predicting a text doesn’t necessarily mean that [a model] is understanding the text,” Melanie Mitchell, a computer scientist who studies AI and cognition at the Santa Fe Institute, told me. Another example: GPT-4 is far better at generating acronyms using the first letter of each word in a phrase than the second, suggesting that rather than understanding the rule behind generating acronyms, the model has simply seen far more examples of standard, first-letter acronyms to shallowly mimic that rule. When GPT-4 miscounts the number of r’s in strawberry, or Sora generates a video of a glass of juice melting into a table, it’s hard to believe that either program grasps the phenomena and ideas underlying their outputs.
These shortcomings have led to sharp, even caustic criticism that AI cannot rival the human mind—the models are merely “stochastic parrots,” in Bender’s famous words, or supercharged versions of “autocomplete,” to quote the AI critic Gary Marcus. Altman responded by posting on social media, “I am a stochastic parrot, and so r u,” implying that the human brain is ultimately a sophisticated word predictor, too.
Altman’s is a plainly asinine claim; a bunch of code running in a data center is not the same as a brain. Yet it’s also ridiculous to write off generative AI—a technology that is redefining education and art, at least, for better or worse—as “mere” statistics. Regardless, the disagreement obscures the more important point. It doesn’t matter to OpenAI or its investors whether AI advances to resemble the human mind, or perhaps even whether and how their models “understand” their outputs—only that the products continue to advance.
new reasoning models show a dramatic improvement over other programs at all sorts of coding, math, and science problems, earning praise from geneticists, physicists, economists, and other experts. But notably, o1 does not appear to have been designed to be better at word prediction.
According to investigations from The Information, Bloomberg, TechCrunch, and Reuters, major AI companies including OpenAI, Google, and Anthropic are finding that the technical approach that has driven the entire AI revolution is hitting a limit. Word-predicting models such as GPT-4o are reportedly no longer becoming reliably more capable, even more “intelligent,” with size. These firms may be running out of high-quality data to train their models on, and even with enough, the programs are so massive that making them bigger is no longer making them much smarter. o1 is the industry’s first major attempt to clear this hurdle.
When I spoke with Mark Chen after o1’s September debut, he told me that GPT-based programs had a “core gap that we were trying to address.” Whereas previous models were trained “to be very good at predicting what humans have written down in the past,” o1 is different. “The way we train the ‘thinking’ is not through imitation learning,” he said. A reasoning model is “not trained to predict human thoughts” but to produce, or at least simulate, “thoughts on its own.” It follows that because humans are not word-predicting machines, then AI programs cannot remain so, either, if they hope to improve.
More details about these models’ inner workings, Chen said, are “a competitive research secret.” But my interviews with independent researchers, a growing body of third-party tests, and hints in public statements from OpenAI and its employees have allowed me to get a sense of what’s under the hood. The o1 series appears “categorically different” from the older GPT series, Delip Rao, an AI researcher at the University of Pennsylvania, told me. Discussions of o1 point to a growing body of research on AI reasoning, including a widely cited paper co-authored last year by OpenAI’s former chief scientist, Ilya Sutskever. To train o1, OpenAI likely put a language model in the style of GPT-4 through a huge amount of trial and error, asking it to solve many, many problems and then providing feedback on its approaches, for instance. The process might be akin to a chess-playing AI playing a million games to learn optimal strategies, Subbarao Kambhampati, a computer scientist at Arizona State University, told me. Or perhaps a rat that, having run 10,000 mazes, develops a good strategy for choosing among forking paths and doubling back at dead ends.
Prediction-based bots, such as Claude and earlier versions of ChatGPT, generate words at a roughly constant rate, without pause—they don’t, in other words, evince much thinking. Although you can prompt such large language models to construct a different answer, those programs do not (and cannot) on their own look backward and evaluate what they’ve written for errors. But o1 works differently, exploring different routes until it finds the best one, Chen told me. Reasoning models can answer harder questions when given more “thinking” time, akin to taking more time to consider possible moves at a crucial moment in a chess game. o1 appears to be “searching through lots of potential, emulated ‘reasoning’ chains on the fly,” Mike Knoop, a software engineer who co-founded a prominent contest designed to test AI models’ reasoning abilities, told me. This is another way to scale: more time and resources, not just during training, but also when in use.
Here is another way to think about the distinction between language models and reasoning models: OpenAI’s attempted path to superintelligence is defined by parrots and rats. ChatGPT and other such products—the stochastic parrots—are designed to find patterns among massive amounts of data, to relate words, objects, and ideas. o1 is the maze-running rodent, designed to navigate those statistical models of the world to solve problems. Or, to use a chess analogy: You could play a game based on a bunch of moves that you’ve memorized, but that’s different from genuinely understanding strategy and reacting to your opponent. Language models learn a grammar, perhaps even something about the world, while reasoning models aim to usethat grammar. When I posed this dual framework, Chen called it “a good first approximation” and “at a high level, the best way to think about it.”
Reasoning may really be a way to break through the wall that the prediction models seem to have hit; much of the tech industry is certainly rushing to follow OpenAI’s lead. Yet taking a big bet on this approach might be premature.
For all the grandeur, o1 has some familiar limitations. As with primarily prediction-based models, it has an easier time with tasks for which more training examples exist, Tom McCoy, a computational linguist at Yale who has extensively tested the preview version of o1 released in September, told me. For instance, the program is better at decrypting codes when the answer is a grammatically complete sentence instead of a random jumble of words—the former is likely better reflected in its training data. A statistical substrate remains.
François Chollet, a former computer scientist at Google who studies general intelligence and is also a co-founder of the AI reasoning contest, put it a different way: “A model like o1 … is able to self-query in order to refine how it uses what it knows. But it is still limited to reapplying what it knows.” A wealth of independent analyses bear this out: In the AI reasoning contest, the o1 preview improved over the GPT-4o but still struggled overall to effectively solve a set of pattern-based problems designed to test abstract reasoning. Researchers at Apple recently found that adding irrelevant clauses to math problems makes o1 more likely to answer incorrectly. For example, when asking the o1 preview to calculate the price of bread and muffins, telling the bot that you plan to donate some of the baked goods—even though that wouldn’t affect their cost—led the model astray. o1 might not deeply understand chess strategy so much as it memorizes and applies broad principles and tactics.
Even if you accept the claim that o1 understands, instead of mimicking, the logic that underlies its responses, the program might actually be further from general intelligence than ChatGPT. o1’s improvements are constrained to specific subjects where you can confirm whether a solution is true—like checking a proof against mathematical laws or testing computer code for bugs. There’s no objective rubric for beautiful poetry, persuasive rhetoric, or emotional empathy with which to train the model. That likely makes o1 more narrowly applicable than GPT-4o, the University of Pennsylvania’s Rao said, which even OpenAI’s blog post announcing the model hinted at, stating: “For many common cases GPT-4o will be more capable in the near term.”
But OpenAI is taking a long view. The reasoning models “explore different hypotheses like a human would,” Chen told me. By reasoning, o1 is proving better at understanding and answering questions about images, too, he said, and the full version of o1 now accepts multimodal inputs. The new reasoning models solve problems “much like a person would,” OpenAI wrote in September. And if scaling up large language models really is hitting a wall, this kind of reasoning seems to be where many of OpenAI’s rivals are turning next, too. Dario Amodei, the CEO of Anthropic, recently noted o1 as a possible way forward for AI. Google has recently released several experimental versions of Gemini, its flagship model, all of which exhibit some signs of being maze rats—taking longer to answer questions, providing detailed reasoning chains, improvements on math and coding. Both it and Microsoft are reportedly exploring this “reasoning” approach. And multiple Chinese tech companies, including Alibaba, have released models built in the style of o1.
If this is the way to superintelligence, it remains a bizarre one. “This is back to a million monkeys typing for a million years generating the works of Shakespeare,” Emily Bender told me. But OpenAI’s technology effectively crunches those years down to seconds. A company blog boasts that an o1 model scored better than most humans on a recent coding test that allowed participants to submit 50 possible solutions to each problem—but only when o1 was allowed 10,000 submissions instead. No human could come up with that many possibilities in a reasonable length of time, which is exactly the point. To OpenAI, unlimited time and resources are an advantage that its hardware-grounded models have over biology. Not even two weeks after the launch of the o1 preview, the start-up presented plans to build data centers that would each require the power generated by approximately five large nuclear reactors, enough for almost 3 million homes. Yesterday, alongside the release of the full o1, OpenAI announced a new premium tier of subscription to ChatGPT that enables users, for $200 a month (10 times the price of the current paid tier), to access a version of o1 that consumes even more computing power—money buys intelligence. “There are now two axes on which we can scale,” Chen said: training time and run time, monkeys and years, parrots and rats. So long as the funding continues, perhaps efficiency is beside the point.
The maze rats may hit a wall, eventually, too. In OpenAI’s early tests, scaling o1 showed diminishing returns: Linear improvements on a challenging math exam required exponentially growing computing power. That superintelligence could use so much electricity as to require remaking grids worldwide—and that such extravagant energy demands are, at the moment, causing staggering financial losses—are clearly no deterrent to the start-up or a good chunk of its investors. It’s not just that OpenAI’s ambition and technology fuel each other; ambition, and in turn accumulation, supersedes the technology itself. Growth and debt are prerequisites for and proof of more powerful machines. Maybe there’s substance, even intelligence, underneath. But there doesn’t need to be for this speculative flywheel to spin
Thank for posting the entirety of the article.
The start-up has been building toward this moment since September 12
Nothing ominous at all.
“In OpenAI’s early tests, scaling o1 showed diminishing returns: Linear improvements on a challenging math exam required exponentially growing computing power.”
Sounds like most other drugs, too.
I mean after reading the article, I’m still unsure how this makes ChatGPT any better at the things I’ve found it to be useful for. Proofreading, generating high level overview of well-understood topics, and asking it goofy questions, for instance. If it is ever gonna be a long-term thing, “AI” needs to have useful features at a cost people are willing to pay, or be able to replace large numbers of workers without significant degredation in quality of work. This new model appears to be more expensive without being either of those other things and is therefore a less competitive product.
The new model now that it’s out of preview is performing significantly less “thinking”
Finally
People writing off AI because it isn’t fully replacing humans. Sounds like writing off calculators because they can’t work without human input.
Used correctly and in the right context, it can still significantly increase productivity.
Except it has gotten progressively worse as a product due to misuse, corporate censorship of the engine and the dataset feeding itself.
Yeah, the leash they put it on to keep it friendly towards capitalists is the biggest thing holding it back right now.
‘Jesse, what the fuck are you talking about’.jpg
No, this is the equivalent of writing off calculators if they required as much power as a city block. There are some applications for LLMs, but if they cost this much power, they’re doing far more harm than good.
Imagine if the engineers for computers were just as short sighted. If they had stopped prioritizing development when computers were massive, room sized machines with limited computing power and obscenely inefficient.
Not all AI development is focused on increasing complexity. Much is focused on refinement, and increasing efficiency. And there’s been a ton of progress in this area.
This article and discussion is specifically about massively upscaling LLMs. Go follow the links and read OpenAI’s CEO literally proposing data centers which require multiple, dedicated grid-scale nuclear reactors.
I’m not sure what your definition of optimization and efficiency is, but that sure as heck does not fit mine.
Now that DeepSeek has been released and proven drastically more efficient, just wanted to pop back in and gloat.
Hope this causes you to reexamine your beliefs and biases. Try reading more next time.
Sounds like you’re only reading a certain narrative then. There’s plenty of articles about increasing efficiency, too.
Interesting article. It’s sad to think there will be a wealth gap in accessing these technologies as they are behind paywall.
The monkey’s typing and generating Shakespeare is supposed to show the ridiculousness of the concept of infinity. It does not mean it would happen in years, or millions of years, or billions, or trillions, or… So unless the “AI” can move outside the flow of time and take an infinite amount of time and also then has a human or other actual intelligence to review every single result to verify when it comes up with the right one…yeah, not real…this is what happens when we give power to people with no understanding of the problem much less how to solve it. They come up with random ideas from random slivers of information. Maybe in an infinite amount of time a million CEOs could make a longterm profitable company.