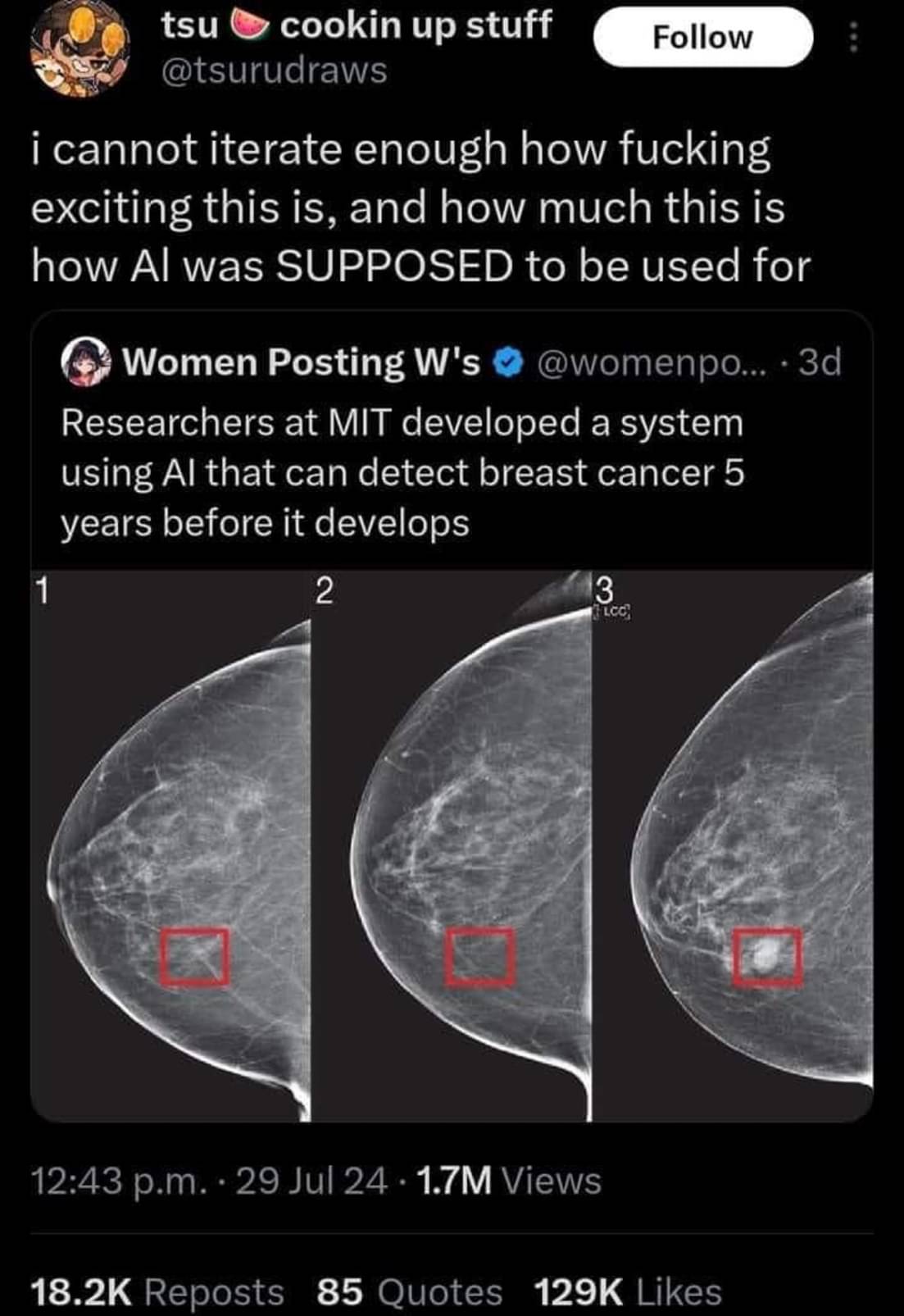
Unfortunately AI models like this one often never make it to the clinic. The model could be impressive enough to identify 100% of cases that will develop breast cancer. However if it has a false positive rate of say 5% it’s use may actually create more harm than it intends to prevent.
That’s just not generally true. Mammograms are usually only recommended to women over 40. That’s because the rates of breast cancer in women under 40 are low enough that testing them would cause more harm than good thanks in part to the problem of false positives.
Nearly 4 out of 5 that progress to biopsy are benign. Nearly 4 times that are called for additional evaluation. The false positives are quite high compared to other imaging. It is designed that way, to decrease the chances of a false negative.
The false negative rate is also quite high. It will miss about 1 in 5 women with cancer. The reality is mammography is just not all that powerful as a screening tool. That’s why the criteria for who gets screened and how often has been tailored to try and ensure the benefits outweigh the risks. Although it is an ongoing debate in the medical community to determine just exactly what those criteria should be.
How would a false positive create more harm? Isn’t it better to cast a wide net and detect more possible cases? Then false negatives are the ones that worry me the most.
It’s a common problem in diagnostics and it’s why mammograms aren’t recommended to women under 40.
Let’s say you have 10,000 patients. 10 have cancer or a precancerous lesion. Your test may be able to identify all 10 of those patients. However, if it has a false positive rate of 5% that’s around 500 patients who will now get biopsies and potentially surgery that they don’t actually need. Those follow up procedures carry their own risks and harms for those 500 patients. In total, that harm may outweigh the benefit of an earlier diagnosis in those 10 patients who have cancer.
Another big thing to note, we recently had a different but VERY similar headline about finding typhoid early and was able to point it out more accurately than doctors could.
But when they examined the AI to see what it was doing, it turns out that it was weighing the specs of the machine being used to do the scan… An older machine means the area was likely poorer and therefore more likely to have typhoid. The AI wasn’t pointing out if someone had Typhoid it was just telling you if they were in a rich area or not.
The thing is tho… It has a better detection rate ON THE SAMPLES THEY HAD but because it wasn’t actually detecting anything other than wealth there was no way for them to trust it would stay accurate.
Right, there’s typically separate “training” and “validation” sets for a model to train, validate, and iterate on, and then a totally separate “test” dataset that measures how effective the model is on similar data that it wasn’t trained on.
If the model gets good results on the validation dataset but less good on the test dataset, that typically means that it’s “over fit”. Essentially the model started memorizing frivolous details specific to the validation set that while they do improve evaluation results on that specific dataset, they do nothing or even hurt the results for the testing and other datasets that weren’t a part of training. Basically, the model failed to abstract what it’s supposed to detect, only managing good results in validation through brute memorization.
I’m not sure if that’s quite what’s happening in maven’s description though. If it’s real my initial thoughts are an unrepresentative dataset + failing to reach high accuracy to begin with. I buy that there’s a correlation between machine specs and positive cases, but I’m sure it’s not a perfect correlation. Like maven said, old areas get new machines sometimes. If the models accuracy was never high to begin with, that correlation may just be the models best guess. Even though I’m sure that it would always take machine specs into account as long as they’re part of the dataset, if actual symptoms correlate more strongly to positive diagnoses than machine specs do, then I’d expect the model to evaluate primarily on symptoms, and thus be more accurate. Sorry this got longer than I wanted
It’s no problem to have a longer description if you want to get nuance. I think that’s a good description and fair assumptions. Reality is rarely as black and white as reddit/lemmy wants it to be.


{kind=link}
Unfortunately AI models like this one often never make it to the clinic. The model could be impressive enough to identify 100% of cases that will develop breast cancer. However if it has a false positive rate of say 5% it’s use may actually create more harm than it intends to prevent.
That’s why these systems should never be used as the sole decision makers, but instead work as a tool to help the professionals make better decisions.
Keep the human in the loop!
Breast imaging already relys on a high false positive rate. False positives are way better than false negatives in this case.
That’s just not generally true. Mammograms are usually only recommended to women over 40. That’s because the rates of breast cancer in women under 40 are low enough that testing them would cause more harm than good thanks in part to the problem of false positives.
Nearly 4 out of 5 that progress to biopsy are benign. Nearly 4 times that are called for additional evaluation. The false positives are quite high compared to other imaging. It is designed that way, to decrease the chances of a false negative.
The false negative rate is also quite high. It will miss about 1 in 5 women with cancer. The reality is mammography is just not all that powerful as a screening tool. That’s why the criteria for who gets screened and how often has been tailored to try and ensure the benefits outweigh the risks. Although it is an ongoing debate in the medical community to determine just exactly what those criteria should be.
How would a false positive create more harm? Isn’t it better to cast a wide net and detect more possible cases? Then false negatives are the ones that worry me the most.
It’s a common problem in diagnostics and it’s why mammograms aren’t recommended to women under 40.
Let’s say you have 10,000 patients. 10 have cancer or a precancerous lesion. Your test may be able to identify all 10 of those patients. However, if it has a false positive rate of 5% that’s around 500 patients who will now get biopsies and potentially surgery that they don’t actually need. Those follow up procedures carry their own risks and harms for those 500 patients. In total, that harm may outweigh the benefit of an earlier diagnosis in those 10 patients who have cancer.
Another big thing to note, we recently had a different but VERY similar headline about finding typhoid early and was able to point it out more accurately than doctors could.
But when they examined the AI to see what it was doing, it turns out that it was weighing the specs of the machine being used to do the scan… An older machine means the area was likely poorer and therefore more likely to have typhoid. The AI wasn’t pointing out if someone had Typhoid it was just telling you if they were in a rich area or not.
That is quite a statement that it still had a better detection rate than doctors.
What is more important, save life or not offend people?
The thing is tho… It has a better detection rate ON THE SAMPLES THEY HAD but because it wasn’t actually detecting anything other than wealth there was no way for them to trust it would stay accurate.
Citation needed.
Usually detection rates are given on a new set of samples, on the samples they used for training detection rate would be 100% by definition.
Right, there’s typically separate “training” and “validation” sets for a model to train, validate, and iterate on, and then a totally separate “test” dataset that measures how effective the model is on similar data that it wasn’t trained on.
If the model gets good results on the validation dataset but less good on the test dataset, that typically means that it’s “over fit”. Essentially the model started memorizing frivolous details specific to the validation set that while they do improve evaluation results on that specific dataset, they do nothing or even hurt the results for the testing and other datasets that weren’t a part of training. Basically, the model failed to abstract what it’s supposed to detect, only managing good results in validation through brute memorization.
I’m not sure if that’s quite what’s happening in maven’s description though. If it’s real my initial thoughts are an unrepresentative dataset + failing to reach high accuracy to begin with. I buy that there’s a correlation between machine specs and positive cases, but I’m sure it’s not a perfect correlation. Like maven said, old areas get new machines sometimes. If the models accuracy was never high to begin with, that correlation may just be the models best guess. Even though I’m sure that it would always take machine specs into account as long as they’re part of the dataset, if actual symptoms correlate more strongly to positive diagnoses than machine specs do, then I’d expect the model to evaluate primarily on symptoms, and thus be more accurate. Sorry this got longer than I wanted
It’s no problem to have a longer description if you want to get nuance. I think that’s a good description and fair assumptions. Reality is rarely as black and white as reddit/lemmy wants it to be.
deleted by creator