
Copyright Sceptic
A twenty-something-year-old man with a knack for doodling, writing, piano playing, and wearing socks of questionable design.
My comments are not protected by copyright. Do what you want with them.
- 10 Posts
- 20 Comments

“Parry this, Google and Facebook!”


 5·2 years ago
5·2 years agoI’m doing my part in opting out of copyright because fuck capitalism
I’d be publishing written works in the public domain but I like to be attributed, so copyleft will do for now, it’s catchy
Doesn’t look like it. The book is quite recent (2020)
What “rights” are there in the first place? This measure hurts the customer in the long run
There are a couple of files, actually.
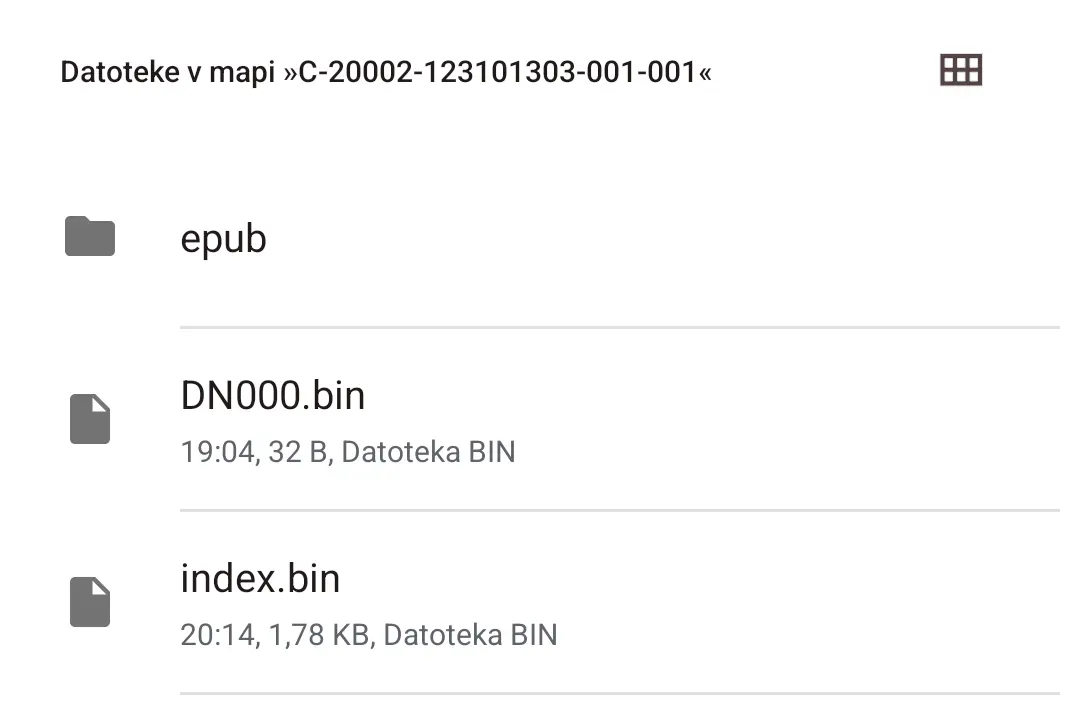

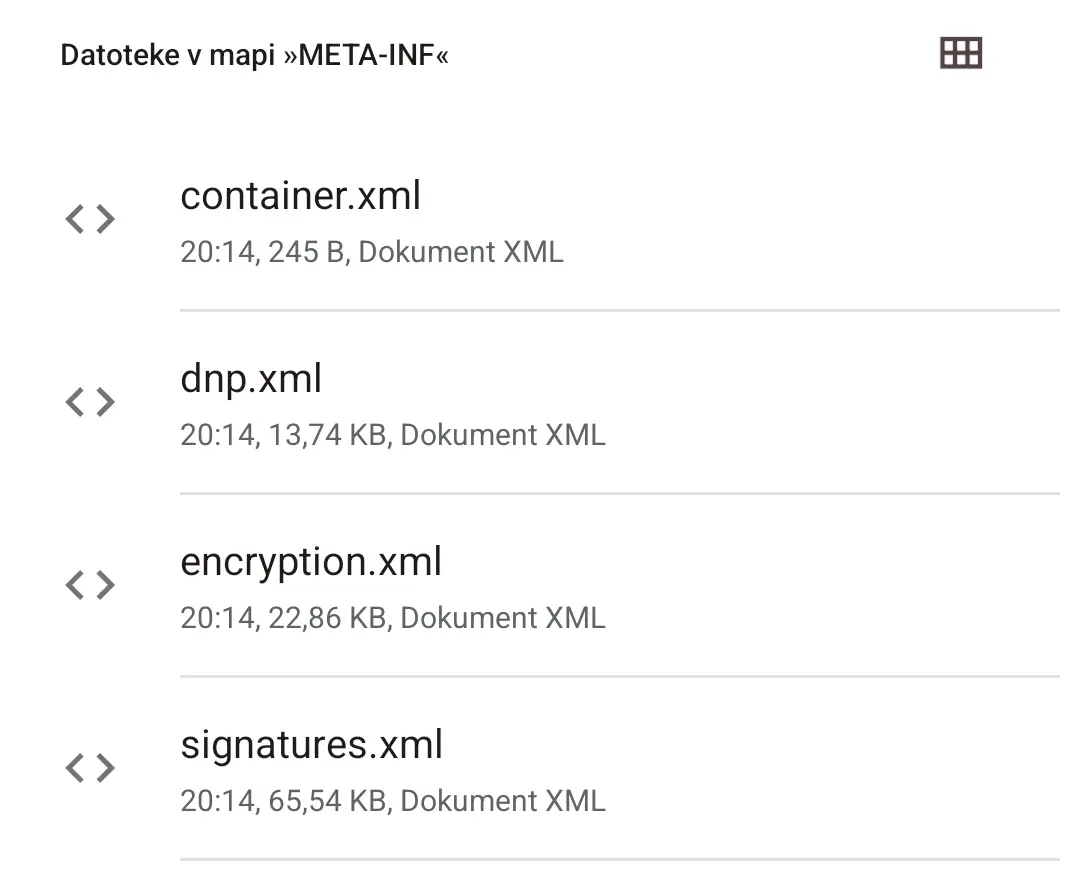
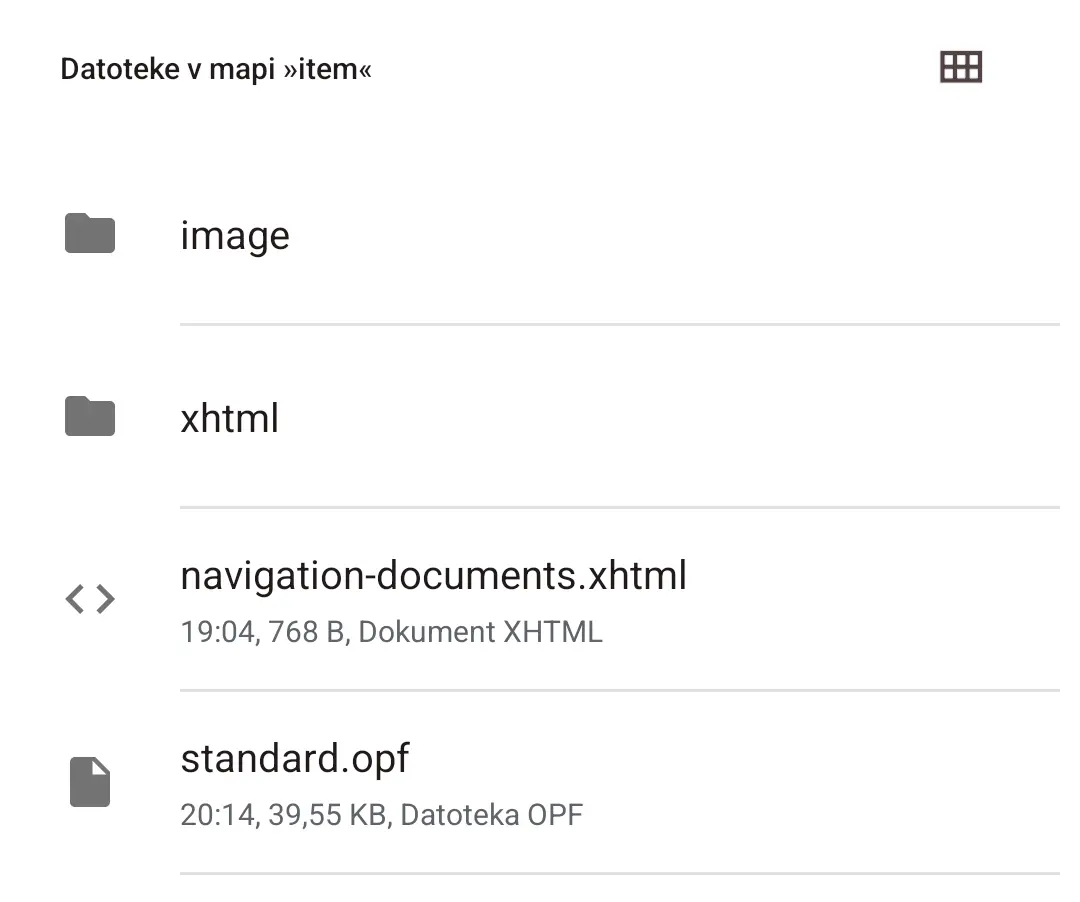
image and xhtml folders have the same amount of files (137), but the former has them in the jpg format, while the latter has them in the xhtml format.
Sorry for haphazardly explaining it like this, I’m on mobile.
Purina
So Nestlé, pretty much?
Obligatory Fuck Nestlé, btw
We still don’t know the secret behind Meghan Markle’s hair… besides deep hydration maybe

It’s fucking raw, so much so that it is still growing…
Btw I have taken this picture straight from a bookstore
Now this is a doubleplusgood meme
Jeez, no need to call me out like that!
 1·2 years ago
1·2 years agoTime to consider the other direction, then. What’s the opposite of ‘right’? Besides ‘wrong’, I mean

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
I use an app with a similar name (MemeTastic, but it makes those image macros, though), but I don’t need to pay anything AND there is no watermark on any meme!

Edit: spelling error or something of the sort
Personally, I believe copyright should last five years max, but I understand this is merely a hypothesis and not everyone has to agree, but that’s the beauty of mankind. Additionally, the beauty of the Fediverse is anyone is capable of finding their own safe haven which shares their views =)
Gonna commit copyright infringement later, just to spite this poor man even more
{kind=link}
Never paid for a streaming service, never will (we’ll see if that changes when I get married)
currently not allowed
currently
🤔 Hold your horses, mateys!
{kind=link}
I found an excruciatingly manual method of extracting comics which I purchased, but it works well
To make it a lot simpler, a Discord user made a script (with the help of AI) which takes the scrambled .jpg image and the tag (e.g. 3,4,7,14,0,13,12,11,6,10,2,8,15,5,1,9) and then uses ImageMagick to unscramble that image. Then I may have to edit the image manually (the edges for example are not scrambled so I have to edit those in)
I’d love to share the script with those who use Honto and would benefit from it, just gotta know if it’s alright with this community